Cluster-based Collection Selection in Uncooperative Distributed Information Retrieval
by Bertold van Voorst
Abstract
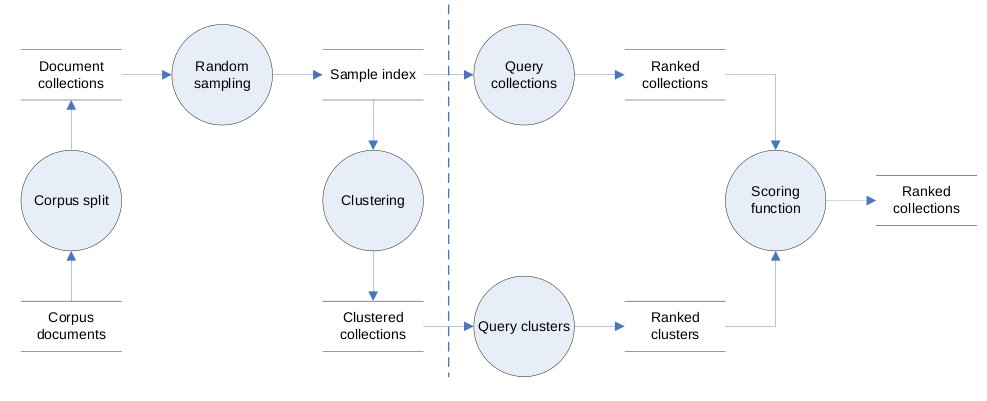
The focus of this research is collection selection for distributed information retrieval. The collection descriptions that are necessary for selecting the most relevant collections are often created from information gathered by random sampling. Collection selection based on an incomplete index constructed by using random sampling instead of a full index leads to inferior results.
In this research we propose to use collection clustering to compensate for the incompleteness of the indexes. When collection clustering is used we do not only select the collections that are considered relevant based on their collection descriptions, but also collections that have similar content in their indexes. Most existing cluster algorithms require the specification of the number of clusters prior to execution. We describe a new clustering algorithm that allows us to specify the sizes of the produced clusters instead of the number of clusters.
Our experiments show that that collection clustering can indeed improve the performance of distributed information retrieval systems that use random sampling. There is not much difference in retrieval performance between our clustering algorithm and the well-known k-means algorithm. We suggest to use the algorithm we proposed because it is more scalable.