Near-real Time Statistics Gathered from a Continuous and Voluminous Data Mutation Stream
by Koen Lavooij
Abstract
The amount of digital data is growing fast. Providing that information as a service is not enough, with the amount of information available. To support the users in finding information, supporting systems have been developed to extract specific information from a large amount of stored data.
Finding or extracting interesting information is as least as important as providing the original data. The “collective intelligence? of a large number of users can be used to order the information. The ordered information is of much greater value when compared to the unordered information, because it provides the user with an overview of interesting and less interesting information.
Current database systems are not able to provide ranked information by analyzing a massive amount of user feedback (e.g. clicks) within a short period of time. Therefore, the systems update the answers periodically.
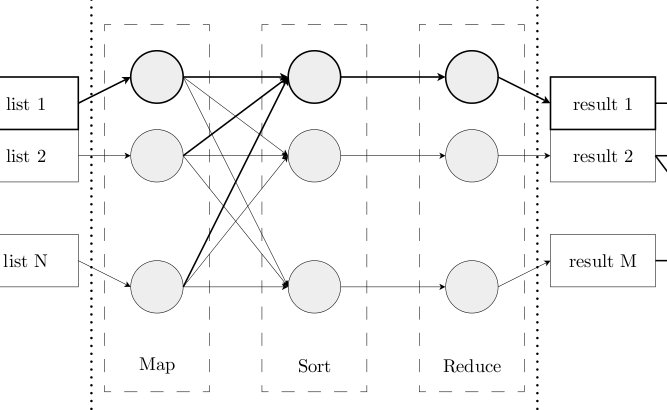
In this thesis, a Stream Processing Engine (SPE) is being adapted. The modified SPE accepts a stream of mutations to a virtual data storage as opposed a stream of tuples. The newly created system exploits the properties of statistical functions in order to efficiently aggregate live statistics over a large stream of mutations.
The newly created system is able to provide answers to a small set of continuous queries. The answers to the queries will be continuously maintained, instead of recalculated. Therefore, the system is able to provide the answers to the continuous queries instantly and with low latency for a large number of users.