Collection Selection for Distributed Web Search using Highly Discriminative Keys, Query-driven Indexing and PageRank.
by Sander Bockting
Abstract
Current popular web search engines, such as Google, Live Search and Yahoo!, rely on crawling to build an index of the World Wide Web. Crawling is a continuous process to keep the index fresh and generates an enormous amount of data traffic. By far the largest part of the web remains unindexed, because crawlers are unaware of the existence of web pages and they have difficulties crawling dynamically generated content. These problems were the main motivation to research distributed web search.
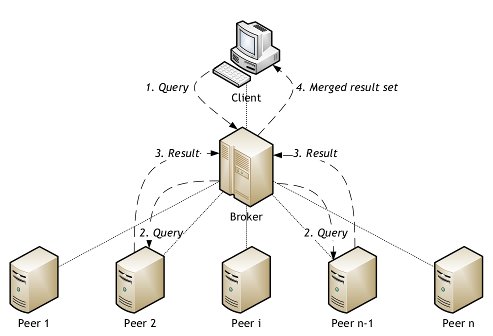
We assume that web sites, or peers, can index a collection consisting of local content, but possibly also content from other web sites. Peers cooperate with a broker by sending a part of their index. Receiving indices from many peers, the broker gains a global overview of the peers’ content. When a user poses a query to a broker, the broker selects a few peers to which it forwards the query. Selected peers should be promising to create a good result set with many relevant documents. The result sets are merged at the broker and sent to the user. This research focuses on collection selection, which corresponds to the selection of the most promising peers. The use of highly discriminative keys is employed as a strategy to select those peers. A highly discriminative key is a term set which is an index entry at the broker. The key is highly discriminative with respect to the collections because the posting lists pointing to the collections are relatively small. Query-driven indexing is applied to reduce the index size by only storing index entries that are part of popular queries. A PageRank-like algorithm is also tested to assign scores to collections that can be used for ranking.
The Sophos prototype was developed to test these methods. Sophos was evaluated on different aspects, such as collection selection performance and index sizes. The performance of the methods is compared to a baseline that applied language modeling onto merged documents in collections. The results show that Sophos can outperform the baseline with ad-hoc queries on a web based test set. Query-driven indexing is able to substantially reduce index sizes against a small loss in collection selection performance. We also found large differences in the level of difficulty to answer queries on various corpus splits.