Query-Based Sampling using Snippets

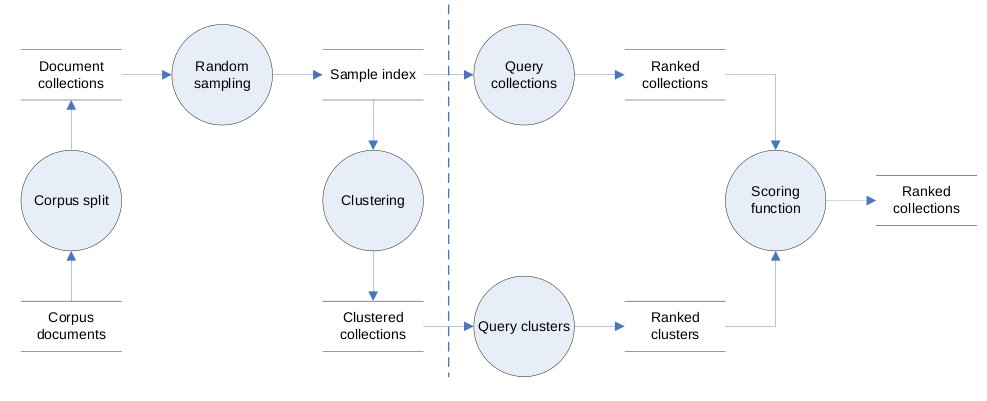
Query-Based Sampling using SnippetsTigelaar, A. S. & Hiemstra, D.In Proceedings of LSDS-IR 2010, Geneva, Switzerland (pp. 9-14). View in Repository Abstract Query-based sampling is a commonly used approach to model the content of servers. Conventionally, queries are sent to a server and the documents in the search results returned are downloaded in full as representation… [Continue Reading]