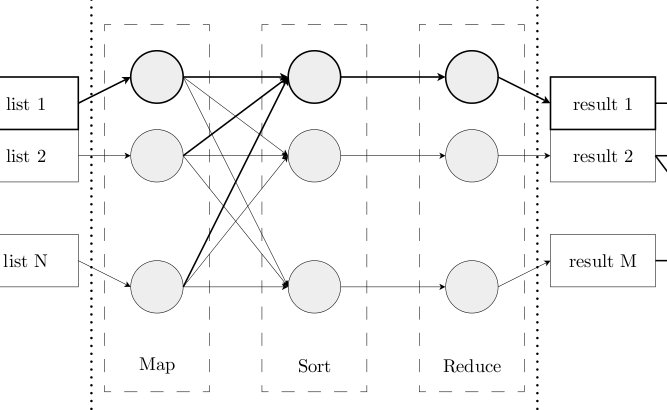
Query-Based Sampling: Can we do Better than Random?

Query-Based Sampling: Can we do Better than Random?Tigelaar, A. S. & Hiemstra, D.Technical Report TR-CTIT-10-04 (2010), Centre for Telematics and Information Technology,University of Twente, Enschede, The Netherlands, ISSN 1381-3625. View in Repository Abstract Many servers on the web offer content that is only accessible via a search interface. These are part of the deep web…. [Continue Reading]